




📃 HTTP is a protocol for transferring web pages, text, media, binary files and much more. It stands for hyper text transfer protocol. It is what the internet pretty much runs on.
🛠 Client-server architecture
The client is 99% a browser, python or a JS app, or any app that has the ability to make an HTTP request.
The server on the other hand, is a web server like for example IIS (Internet Information services), Apache, Tomcat, NodeJS, Python Tornado etc.
The protocol is a standard for all modern browsers to communicate with the server to transmit and receive data over the network.
Google has a major contribution to HTTP2.0 and 3.0 (experimental).
Request
There are 4 properties in every HTTP request:
URL: The resource location from where you want to either serve content or send data to. Most commonly our domain name is the URL we want to use.
Method type: Semantics used to define the action taking place over the URL. Considering an example of serving an image, in order to render the image on the browser, the GET method is used to read from the server and then display it.
Headers: Defines the metadata of content being transmitted. There are several types of headers like the host, any cookies etc.
Body: Certain method types require a body like POST. It contains data which is to be stored on the server or on a remote database.
🤔 How does HTTP work ?
- It is a protocol which operates on layer 7 of the OSI model.
- It uses TCP which works on layer 4, to communicate with the server on the other end because of the information it puts into every packet.
- The first thing a client does is open a connection. TCP uses the three-way handshaking concept to establish a connection before going ahead with the request.

Once the connection is established, the HTTP request is made. The server receives the request, processes it, and sends back the response.
On receiving the response, the TCP connection is closed. There could be multiple packets being transferred in one connection if the payload is large enough to fit in one.
The opening and closing a connection has a cost to pay by the client.
HTTPS
The TLS handshake takes place to enable a secure connection over HTTP.
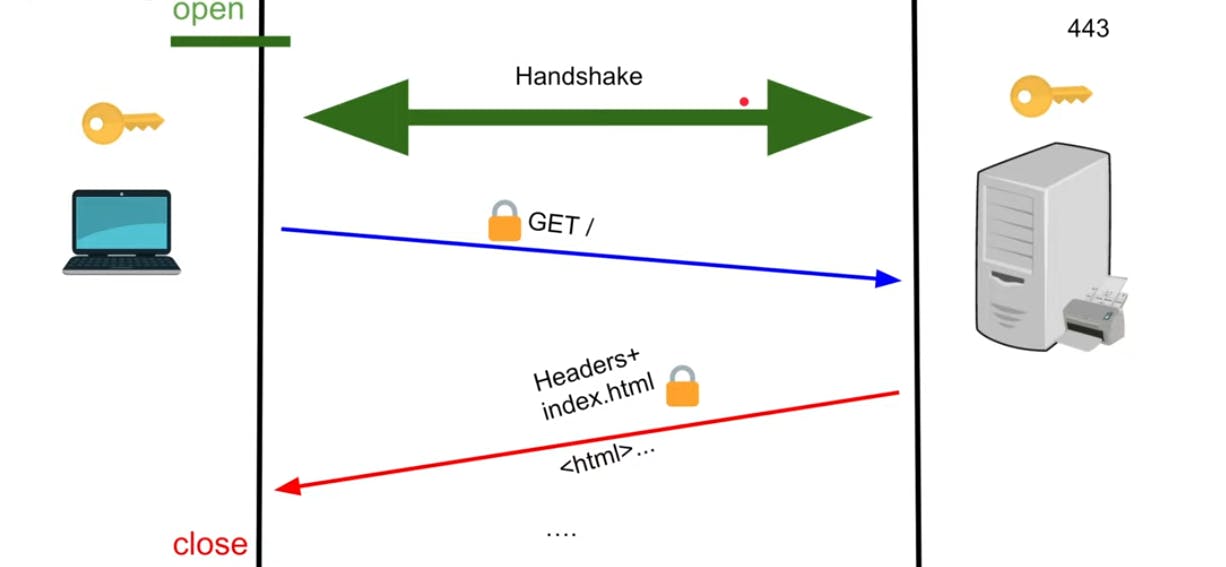
- Both the client and the server have the key to unlock the request and response in order to prevent sniffing of packets between the two parties.
HTTP/1.0
Came into practice in 1996.
On every request by the client, a TCP connection opens up on both the sides, and on receiving the response it is closed. This becomes an expensive task when we consider multiple requests being made.
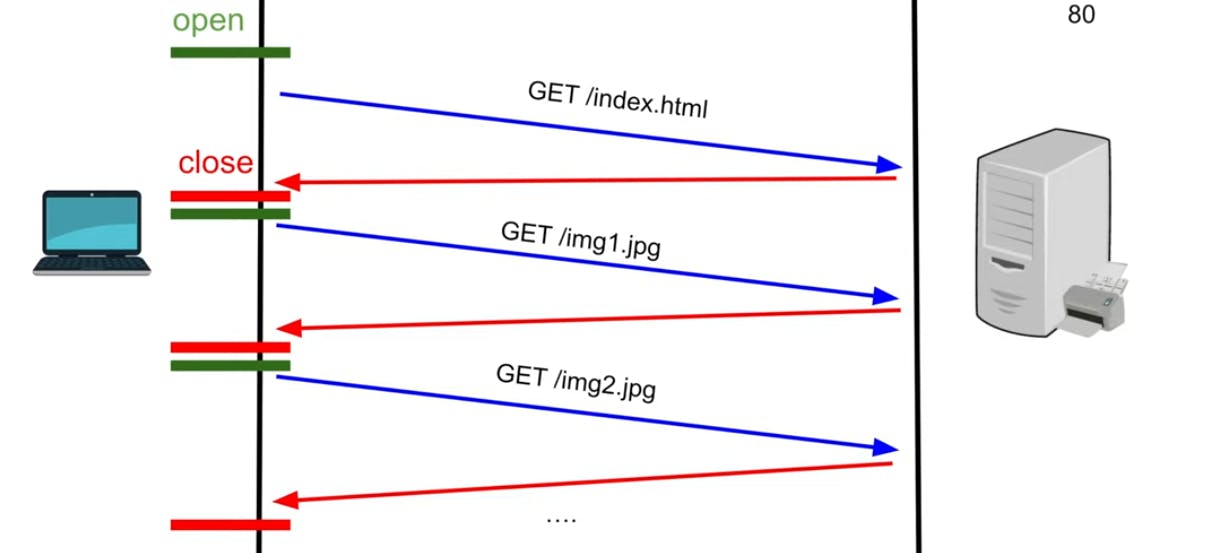
For TCP, opening up a connection to a remote machine is slow. There is a problem called tcp slow start. It has to do a bunch of things like congestion control, reordering packets etc.
It uses buffering to send data. If there is a large index.html file, the sends the data while simultaneously building up slowly.
HTTP/1.1
The version 1.0 was pulled off a year after because of its huge expensive cost on opening TCP connections for each and every request.
1.1 came into practice in 1997, until in 2015 HTTP2 became a real thing.
This version had a new header known as keep-alive. It's a header for the server which keeps the connection open for a certain amount of time. It allows the client to send multiple requests just by using one TCP connection!
Along with this major change, it also brought in caching by introducing etags.
Due to the advantage of having a persisted connection, we have lower latency. As 1.0 used the technique of buffering, 1.1 uses streaming with transferring chunks of data allowing the content to render on the browser and not wait for it to load fully.
HTTP/2
It was designed to solve 1.1 problems.
Multiplexing is an idea where multiple requests are shoved into one channel. It means the requests are sent onto a single TCP connection as one request. Hence, we do not encounter the problem of reordering in case of HTTP pipe lining which was introduced by 1.1.
It uses compression just like protocol buffers, an open source format designed by Google.
It is stateless although under the hood it uses TCP which is stateful. But if the server dies, and we spin it up again, it doesn't hold any information before the downtime of the machine.
By default it is secure.
These are points which I have noted while learning HTTP & its evolution. Thank you for stopping by! 👋
Inspired by Hussein Nasser